Deepseek has silently released a bombshell update to the Deepseek v3 base model. And surprisingly, it went under the carpet amid the Chatgpt image generation launch. It has improved over its predecessor in reasoning and coding. The current coding champion (in raw output) is Claude 3.7 Sonnet.
I was intrigued by how much of an improvement Deepseek v3 0324 is over the original one. It matched GPT-4o, and from the benchmarks, it is on par with the Sonnets.
So, let's get started.
Deepseek V3-0324 Details
Here are some key details worth noting about the new v3 checkpoint:
🧠 685B MoE parameters
🚀 641 GB of total size in full-precision
💻 Better code-generation abilities
🛠️ Smarter tool-use capabilities
🏃♂️➡️Improved reasoning, thanks to RL training with GRPO
🧩 Open Sources under MIT License
Deepseek v3 0324 scores higher on benchmarks
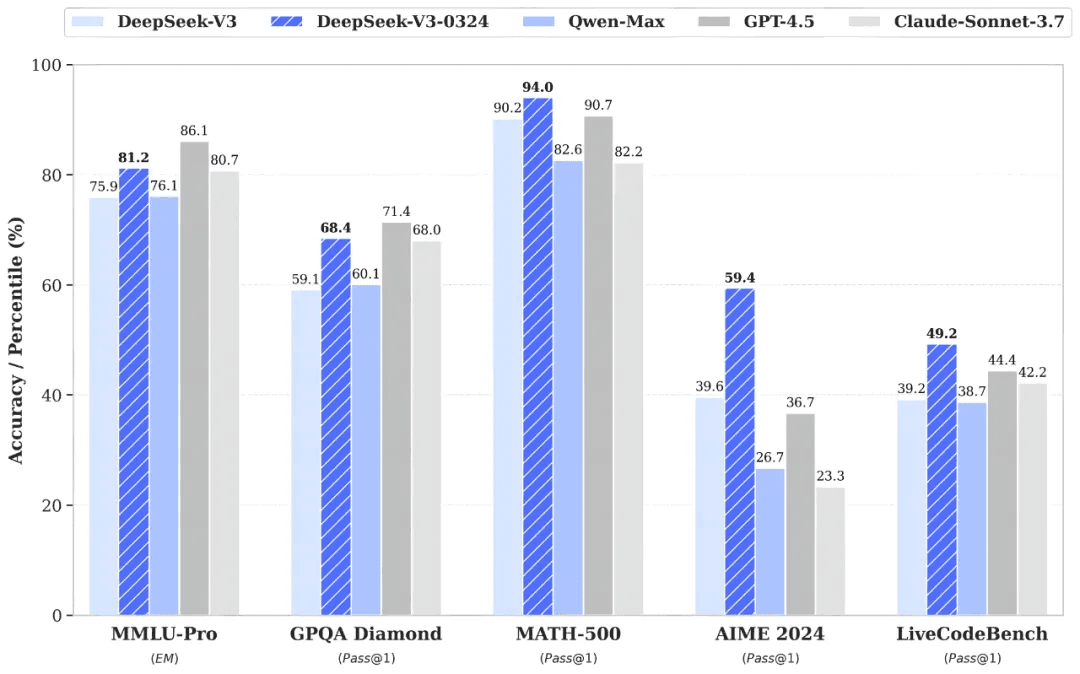
credits: Deepseek official docs
To Learn More:
Having known the specifications, let’s now evaluate the model's performance.
Evaluating Coding Performance
As we will compare the model against Claude 3.7 Base, which is a beast in terms of coding, let’s compare Deepseek V3 performance against the same benchmarks for a level comparison.
For the evaluation test, I will select 4 to 5 examples from my curated set and assess the performance of both models on the given task. Additionally, points will be given to winners. In case of a tie, each contender receives 1 point.
We will compare the output based on code length, quality and response quality.
So, let’s start!
Test 1: 3js simulation
Prompt: Create a 3JS simulation of a metropolitan cityscape.
This test shows how good a model is at 3JS and their internal creativity. This is a zero-shot test, so all the simulation code was generated in one go. Here are the responses from the respective models.
Deepseek v3 0324:
The generated cityscape is clean, and the buildings, roads, and even traffic are defined. Although the movements weren't working, the traffic toggle was functioning correctly.
Claude 3.7 Sonnet:
The buildings and roads are less detailed than Deepseeks's, but the movement worked; it was a first-person perspective simulation.
Deepseek was better overall regarding artefacts and animation, but fixing the navigation would have taken another prompt. Deepseek v3 0324 won this round, so Deepseek gets one point.
Off to test No. 2
Test 2: LeetCode - Problem #2861 Solution
For the next test, I will use a tricky question for the Leet Code: “Power of heroes.” Most of the LLMs tested earlier solved this problem with reasonable accuracy. Let’s see if Deep Seek V3 and Claude Sonnet 3.7 keep up the pace.
Prompt
If both models might solve the challenge, the evaluation will be based on Time, Space complexity, and response output time.
Let’s check the outputs.
Output: Deep Seek V3 (Code -67.7s )
Results
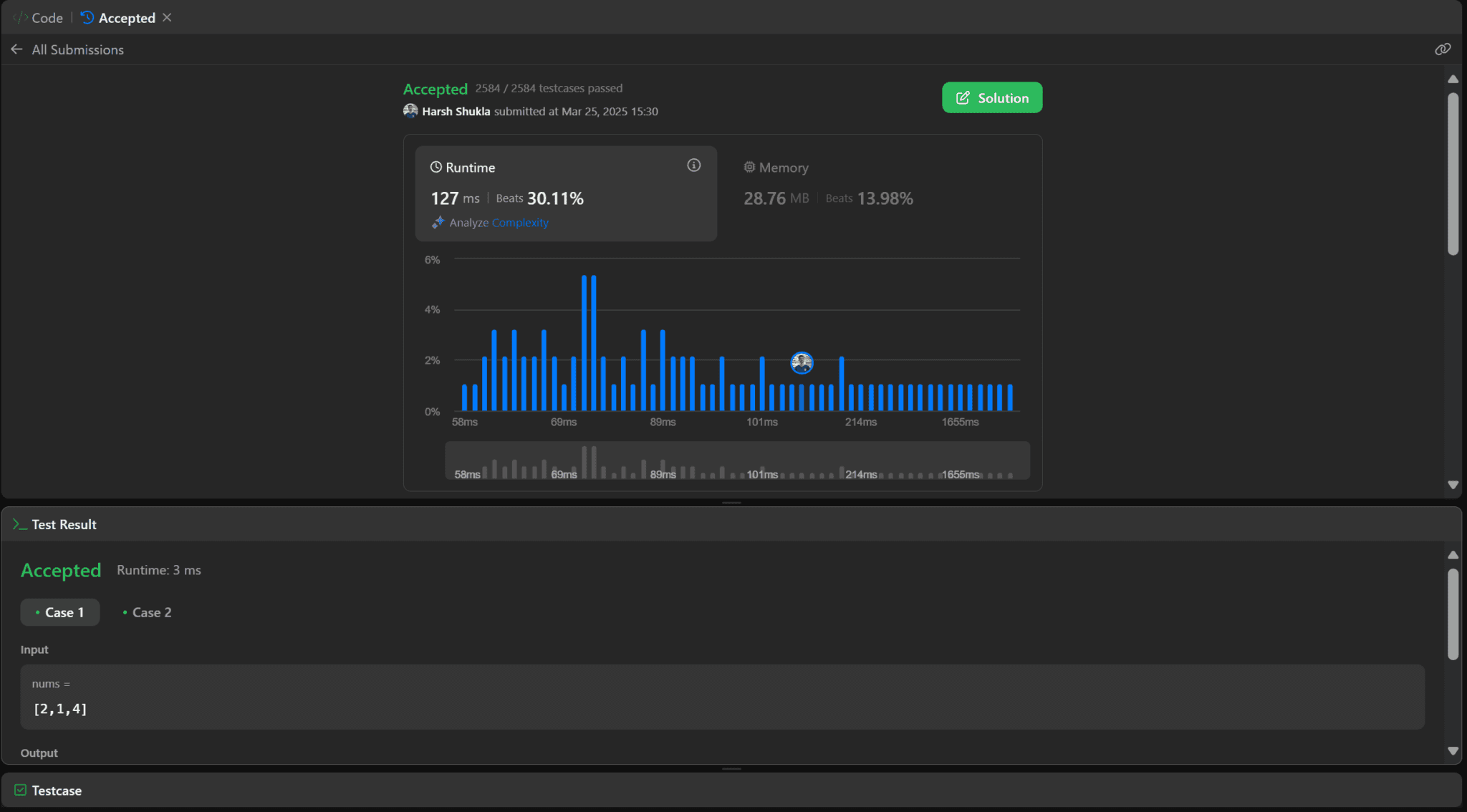
Deep Seek V3 solved the code and handled the Time & Space Complexity as instructed.
As for code quality, it is long, well-explained, documented, straightforward and easy to follow.
Now, let’s see how Sonnet 3.7 Performs!
Output: Claude Sonnet 3.7 Base (Code - 16.5s)
Results:
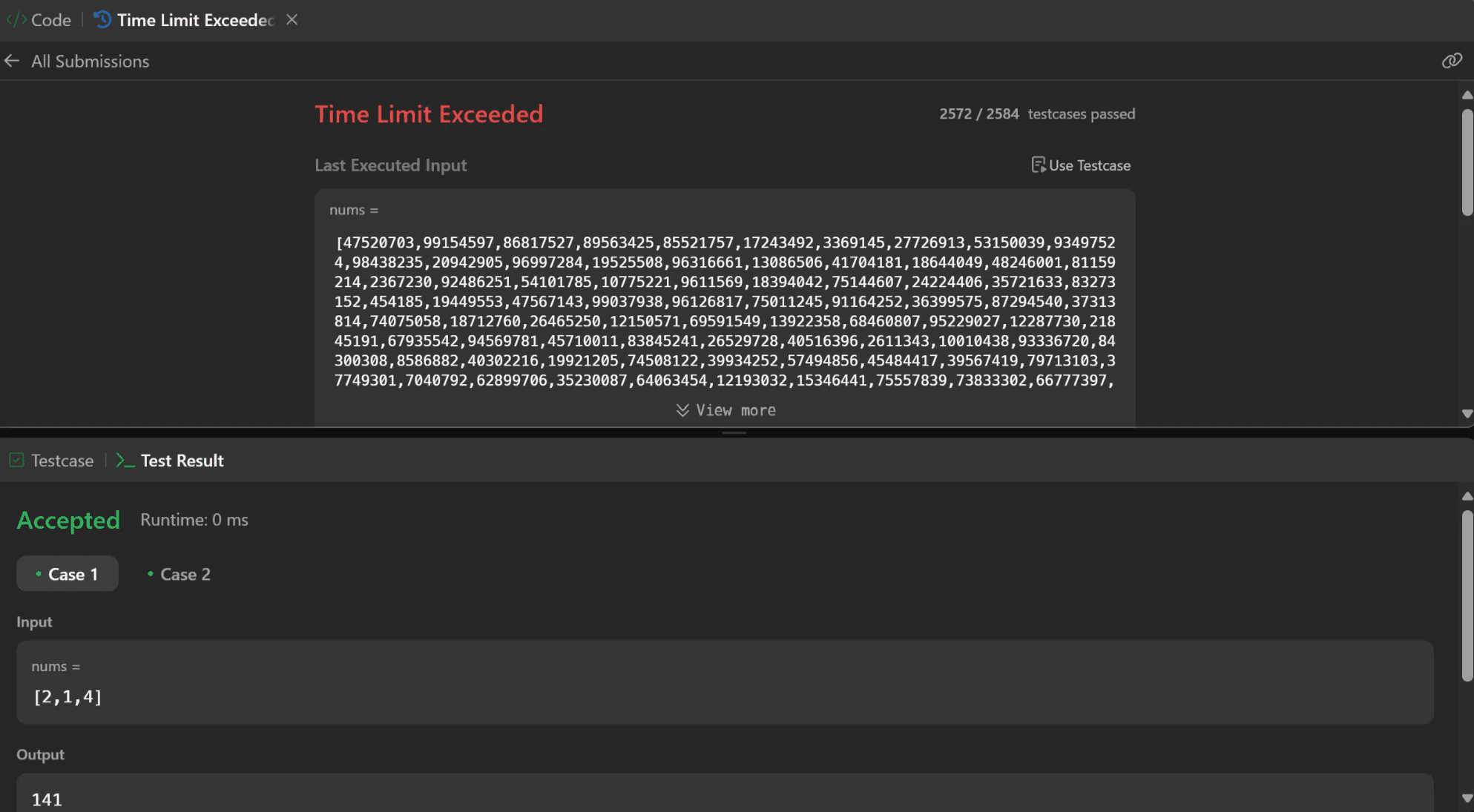
The model-generated code passed the public test cases but failed to handle Time Complexity.
The code quality is good, well explained, documented, clear, concise, and easy to follow.
Final Thoughts
Deep Seek V3 code was long and explanatory with high response time, but passed the test cases and handled the time and space complexity.
Sonnet on the other hand responded with shorter cleaner code with low response time but failed to pass the private test cases.
If I prepare for Coding Exams & Interviews, I will go for Deep Seek V3 for code references.
Current Score: Deep Seek v3 - 2, Claude Sonnet 3.7 - 1
off to test no 3
Test 3: Leet Code - Problem #3463 Solution
I found this one while writing my other blog, and it became my benchmark question for evaluating LLM's coding capabilities.
This requires first-principle thinking rather than library usage. Let’s see how Deep Seek V3 and Sonnet 3.7 Base perform.
I am personally excited about Deep Seek V3's performance because last time, only Grok3 (Think Mode) was able to solve it!
Prompt
If you look carefully, we have explicitly mentioned that the code needs to be solved using the first principle and must be clear, concise, explanatory, and cover all edge cases.
Though we never mentioned it's a question about Pascal's Triangle, figuring it out is part of the model reasoning process.
Let’s see which one can identify and solve it.
Output: Deep Seek V3
Result
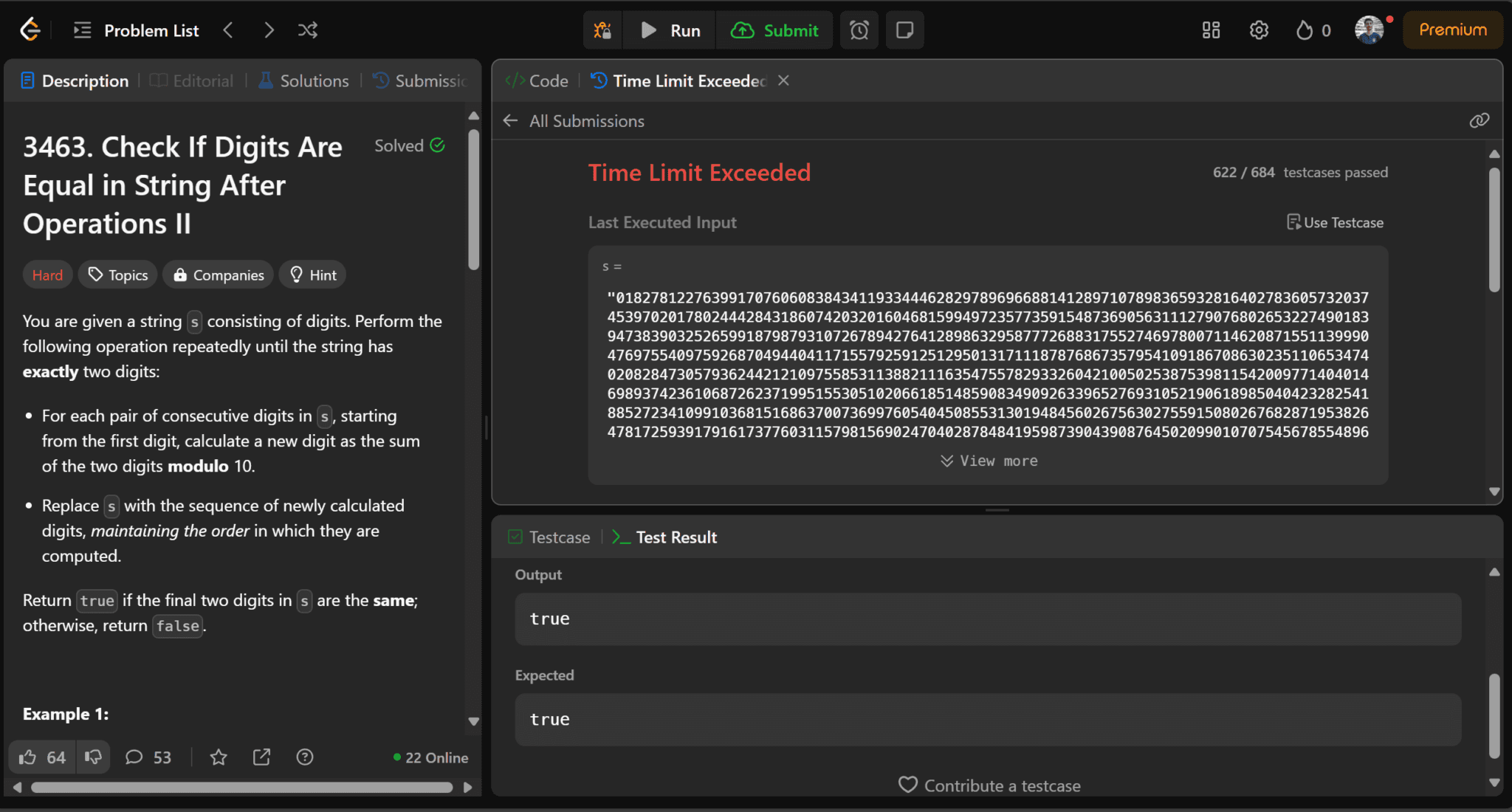
Time Limit Exceeded - Sonnet 3.7 Base
Yup, it’s also failed. So Grok3 still keeps its spot!
Though I liked the concise code, I hated the lack of clear comments and the model's failure to follow the first principal reasoning abilities.
Let’s see how Claude Sonnet 3.7 Performs
Output: Claude Sonnet 3.7
As usual, the sonnet verified its steps, which helped it pass the public test cases, but was not enough to pass the private test case, resulting in a Time Limit Exceed Error.
Time Limit Exceeded - Sonnet 3.7 Base
Though Sonnet also failed, the code was well documented, short and clear. Would go for it!
Final Thoughts
Deep Seek V3 code was short and concise, but the code was not clear (as there were no comments) & model failed to follow the instructions given in the prompt.
On the other hand, Sonnet responded with a more extended code, but it was concise and clear and followed the instructions except for the first principal reasoning through the process to follow.
Current Score: Deep Seek v3 -2, Claude Sonnet 3.7 - 0
Off to test No 4
Test 4: Minecraft Game in Python (One Shot Prompting)
Till now, we have explored 3D Scene Generation and Coding problems; what about building a complete solution.?
So, can Deepseek V3 / Claude Sonnet 3.7 build a full-stack application that handles all the intricacies? Let’s check it out.
For this, let’s build a Minecraft game using Python using One-Shot Prompting
💡Disclaimer: The prompts are taken from Build the full stack application using GPT prompts (article by @rsharma5)
Prompt
Please help me build a straightforward Minecraft game using PyGame in Python.
Output: Deepseek V3
Code: GitHub (deepseek_v3_results.py) + instructions with install instructions.
Results

Deepseek Results
As expected, Deepseek V3 wrote the right code on the first try—impressive. It even cloned Minecraft's building mechanics!
The block palette selection UI isn’t working, and there’s still room for improvement. But overall, I am impressed by the output.
Output: Claude Sonnet 3.7 Base
Code: GitHub (claude_sonnet_3.7_results.py) + instructions with movement details but no install instructions.
Results
I never expected this, but the program crashed. Based on the output, it is a Type error.
After explicit prompting, here are the results(claude_sonnet_3.7_game_results.py):
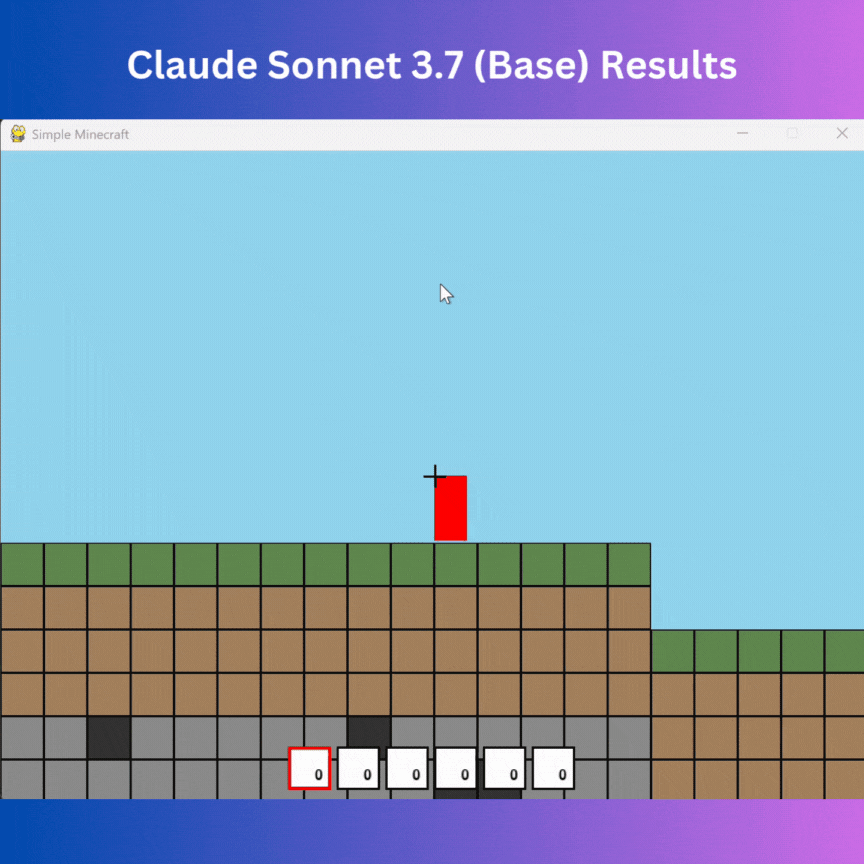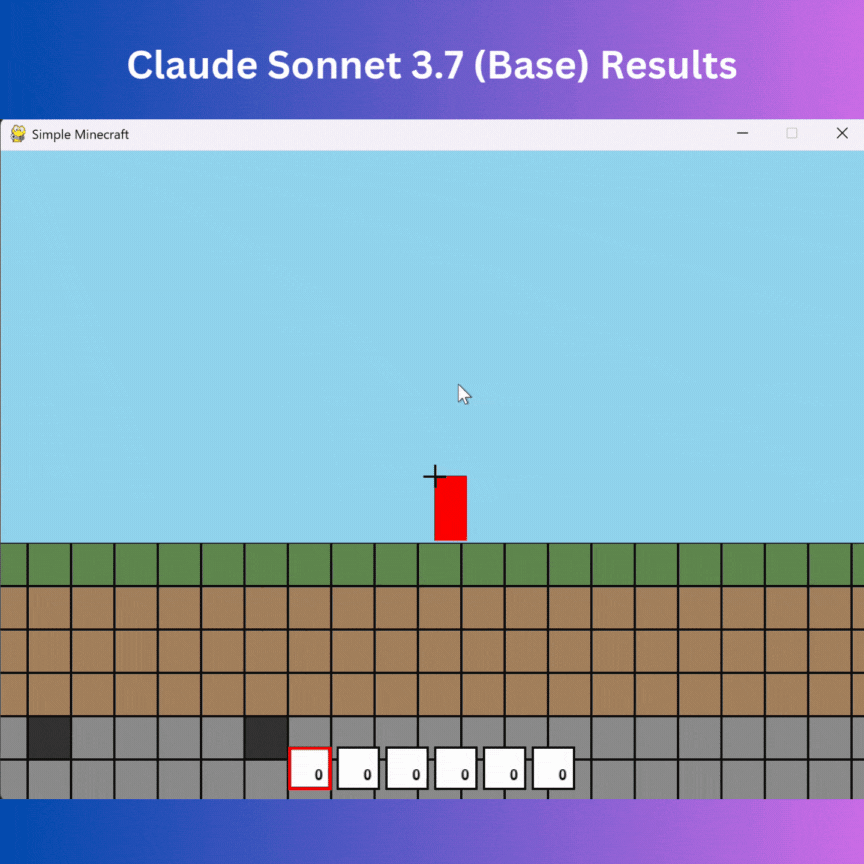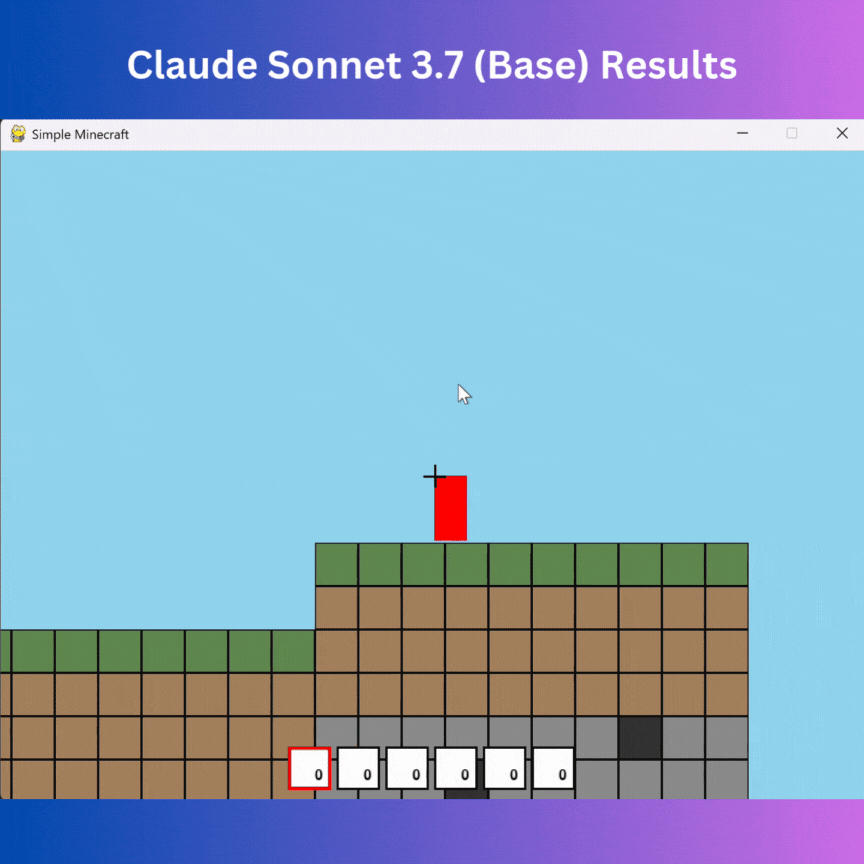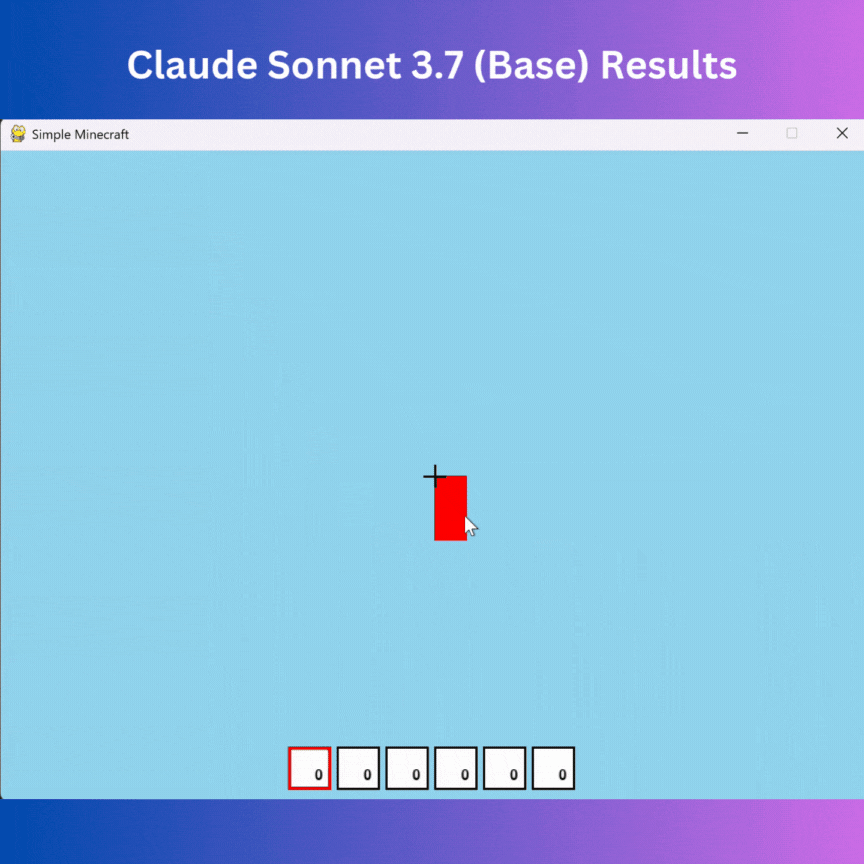
I expected the model to build a Minecraft with functionality to add blocks and movement, but it made something totally different—a 2D Platformer.
There is no way to delete or add blocks; it resembles a 2D platformer with a wobble effect (not what was needed), and there is no button value change in the UI (similar to DeepSeek v3).
Overall, here are my final thoughts on this test.
Final Thoughts
Deep Seek V3 mimicked some parts of Minecraft (adding, deleting, and selecting blocks), followed physics, wrote good code, and ran on the first try.
On the other hand, Sonnet 3.7 Base struggled—it needed multiple prompts, failed physics rules, and had a wobbling effect. While it eventually produced working code, it lacked the expected functionality (adding, removing and selecting blocks).
Do note that both models have the potential to implement different functionalities with the same prompt, but DeepSeek V3 code and output were more polished in terms of One-Shot Prompting.
So, 1 point goes to Deep Seek V3
Current Score: Deep Seek v3 -3, Claude Sonnet 3.7 - 1
Who Aces the Test?
After evaluating model responses over multiple tests:
Claude Sonnet 3.7 Base Score: 1/4
Deepseek V3 Score: 3/4
Winner: Deepseek V3 0324
Final Thoughts
Deep Seek V3 excelled in the simulation, game building, and LeetCode problems (medium difficulty). It scored 3/4, while Sonnet only passed 1/4. It's a very vibe-based test, but it paints a good picture of how capable the new Deepseek v3 0324 is.
The open-source base models have almost closed the gap with the proprietary models. Deepseek v3 0324 is among the top base models of major AI labs and even surpasses many others. It is not even a generation jump but a new checkpoint of the same model that was considered average 3 months back. Nobody will be surprised when Deepseek finally releases a state-of-the-art model this year.